Leaf 0.3 - The Server Behind Roomy
For the last couple months we've been iterating on Roomy with its brand-new architecture, and we're finally ready to talk in more detail about the not-so-secret sauce that will power Roomy moving forward.

If you want some more history on the designs that came before this one definitely read A Brief History of Roomy's Architectures. We've written in the past about using tech like Keyhive, Jazz, and Willow, but the latest design doesn't use any of those for now.
The Core Components
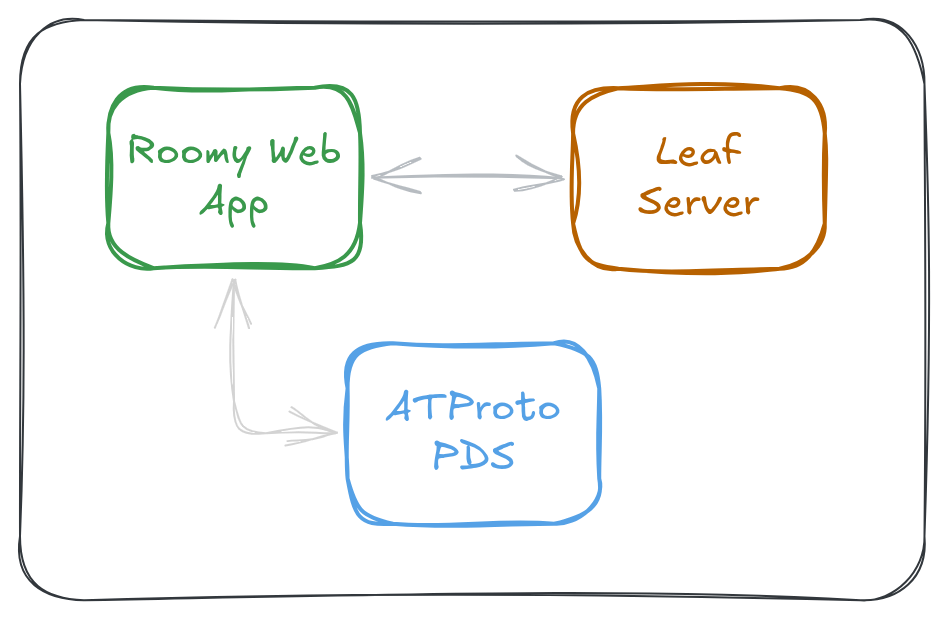
There are three major components to Roomy: the Roomy Web App, the ATProto PDS, and the Leaf Server.
The Leaf Server
The Leaf Server provides storage and realtime sync for Roomy, but it is actually application agnostic: it has no Roomy-specific code in it.
Instead, the server hosts user-defined "modules" that allow you to customize the way that the server handles data for a particular "stream". It's almost like an opinionated kind of PaaS designed specifically for Event Sourcing ( more on that later ).
This is very useful for Roomy because modules can be upgraded by the app without requiring any infrastructure changes. This will make it easier for us add new features to Roomy and try new things out, without having a lot of work to keep the server deployment and the app in sync with each-other.
The server is also very lightweight easy to self-host.
Off Protocol
But if all the data is stored on the Leaf Server, how does ATProto come into play? It sounds like Roomy is off-protocol. 👀
Oh, hey Charlie! It's been a while. That's a good question! In short, yes, Roomy's data is off-protocol.
In Roomy, ATProto is used primarily for authentication and for integrations with other ATProto apps such as Bluesky, Smoke Signal, Streamplace, Semble, and more.
Auth is a really important one because it gives you an experience similar to the ubiquitous "Login with Google" button, but one that still allows you to host your own identity server.
Ah, yeah, we talked about the importance of ATProto's identity integration earlier.
Yep. And while there are absolutely good reasons to use the PDS for storage, we have some technical problems with using it as the official store.
Private Data
The first one is that all data on the PDS is public. There's no way for us to store, for example, chat messages that are sent in a private channel without encrypting it, and publicly distributing encrypted data is not a good practice.
There are great efforts underway to solve the private data problem on ATProto, but they usually involve hosting another server as a sidecar similar to what we are doing with the Leaf server anyway.
Even Bluesky's DMs, and Leaflet's drafts have to be implemented off-protocol.
Many, Tiny, Realtime Events
The other issue is that the PDS isn't necessarily design for streaming lots of small events like chat messages. There are rate limits on writes to the PDS, and the firehose isn't low-enough latency to use for chat synchronization.
Private Data + Notifications
Even if we had a way to store private data on the PDS, if you treat the PDS as the source of truth then your app has to have a way to know when the user changes without using your app.
Right now the firehose is used to notify apps about these kinds of changes, but that doesn't work for private data. There is another layer here that needs to be solved for, in addition to just being able to store private data.
Local First Synchronization
While not working yet, one of our big long-term goals is to have Roomy's data work in a local-first context. You should be able to edit your own data ( which may include far more chat messages ) offline, and sync it with other devices or peers, without a central server.
Depending on ATProto as our canonical data source makes this a lot more difficult manage.
What If We Don't Want to Require an ATProto PDS?
This might be controversial in the ATProto community, but what if we want to let you use Roomy without a PDS? If we already have to implement our own streaming system, our own database to index messages, our own way to query all of those messages in our app, and finally have a way to sync it without servers, then there isn't much the PDS is providing for us anymore. The biggest thing the PDS is providing is a standardized way for users to access their data.
The data access advantage can be preserved by having Roomy do semi-realtime backups of all of your chats to your PDS, in bundles so that we don't have to worry about rate limiting. Note that this unfortunately only works for public chat messages.
Additionally, auth on Leaf server is quite easy to extend to allow other options such as login with Mastodon or OIDC or IndieAuth, and in fact we plan on experimenting with that once Roomy gets more stable.
Being able to function without a PDS feels like an important way to future proof Roomy by focusing on what it actually needs to do its job. While logging into Roomy without a PDS would probably mean you can't use ATProto integrations, maybe logging into Roomy with Mastodon or other services could give you different integrations.
We aren't sure how things will develop, but we feel good about our ability to fit into different scenarios and we aren't ruling anything out.
What Is on the PDS?
So do you store anything on the PDS?
There's a small handful of things we store on the PDS right now:
Public uploads are stored on the PDS. Later we will add a way to store uploads on the Leaf server so that we can support private uploads.
Roomy space handle verifications are stored on the PDS. This is a record that goes on your PDS when you want to use your ATProto handle as the handle for a space. It lets us look up a Roomy Space ID by using your ATProto handle. We're not sure whether these records will be used long-term.
Finally, as mentioned above, biggest thing that we want to be able to put on your PDS is continuous backups of your Roomy data. Unfortunately we still can't backup private data to your PDS, so this will remain limited to public data.
Data Ownership & Migration
OK, but if all of my chat data is stored on the Leaf Server, then how do I have ownership of my data? Having backups of public data helps a little bit, but what about private data? What makes Roomy any different other cloud apps in terms of data ownership?
If we look at the PDS as an example, I think the import "data ownership" features are:
- The PDS can be self-hosted or hosted by a provider,
- You can migrate your PDS hosting between providers,
- There is an API that you can use to access all the data on your PDS.
The Leaf server provides all of these same features very much like the PDS does, but with a different API.
It's really like a different kind of PDS, as I wrote more thoughts on recently.
But just because you have an API doesn't mean that there's any way for normal people to use it. An API alone isn't enough to provide credible exit.
That's an excellent point! We will be providing tools to use the API, similar to tools that already exist for the PDS. But community is important, too. It's best if we aren't the only providers of credible exit features, but that is something that will take time to grow.
How Does It Work?
Let's get to the tech details already! What are modules and streams, and how does Leaf act like a PaaS?
Streams
Almost all data on the Leaf server exists in a stream, and it is similar in purpose to a repo in ATProto.
Unlike user repos in ATProto, Leaf streams are often for communitites, not just individuals. In Roomy, streams represent spaces, similar to Discord guilds, and they allow controlled write and read access from multiple user accounts.
As fellow Roomy developer @meri.garden put it: Leaf as a multi-player PDS.
Stream Identifiers
DIDs are used for stream IDs, just like they are used for ATProto accounts. When you create a new stream, it will create a new DID and publish it to plc.directory. The creator of a stream can add additional rotation keys to the DID that can be used to migrate the stream to a different Leaf server, for example, if the Leaf server goes rogue or you just want to switch hosting providers.
This allows different streams to be hosted on different Leaf servers, and could be used, for example, to self host Roomy space on your own server.
In the future we can add support for other DID methods like DID web.
Stream Data Model
All the data in the stream is represented by events.
Each event has a very simple data model:
- Index: The index of the event in the stream. This is just a number that increments for every event that gets sent into the stream.
- User: The DID of the account that submitted the event to the stream.
- Payload: A binary array containing the event data.
The Leaf server doesn't really care about what data goes into the events, so the payload could be JSON or CBOR or any other binary or text format.
This list of events is stored in a separate SQLite database for each stream.
Modules
Modules are the customizable logic of streams and they are responsible for authorization and aggregation.
Authorization
Before any event is saved to a stream, the event must be authorized by the stream's module.
Additionally, the only way to get an event out of a stream, is to use a query that is defined by the stream's module. This allows the module to perform read authorization.
Finally, for every event that passes write authorization, the module may run a "materializer". This materializer allows the module to cache any info about the event in its own SQLite database.
This database can be used to index events based on things like what channel a chat message was sent in, or what permissions exist for an event. The data can then be used in queries to quickly determine whether or not a user has access to perform the query, and which events should be returned.
Aggregation
The module's database also naturally allows the server to perform aggregations over the events.
For example, it could use SQLite's full text search in order to find chat messages based on a search query, or it could keep statistics like when each channel was last updated.
This aggregate data can then be used in queries for clients.
Updating Modules
While the events in the stream are meant to persist long term, the module and its database can be swapped out as needs change.
For example, if you need to change the way that permissions are applied, you will need to change the module, but the data in the stream shouldn't change.
When you update the stream's module, it will re-run the module's materializer for every event that is already in the stream, allowing the module to index it and re-build any aggregations.
Subscriptions
Queries defined by the module can also be subscribed to, so that if a new event is added to the stream, the query will be re-run and may return the new event if it matches the query. This allows us to get realtime updates in the app.
In the future, this can be made very performant by using Incremental View Maintentance ( IVM ) in Turso. Turso is a rewrite of SQLite in Rust with extra features. It isn't ready enough for us to use yet, but they're making great progress and we're hoping to use it on the Leaf server and in the Roomy app.
For now, re-running queries for subscriptions should still be fast for the most important kinds of queries, which can exclude already sent events by filtering based on event index.
Ephemeral Events
Ephemeral events are a way to send events to the stream that will not be persisted to the stream database. This can be used for things like typing indicators and other online "presence" features.
As another layer on top of this, ephemeral events can have their own materializer that allows you to store persisted state for things that will change frequently but that you only care about the latest state of.
For example, the latest message you have read, which is useful for unread notifications, is going to change constantly, but we don't really need to keep an event history of all the messages you've read. An ephemeral event can be used to notify when you read messages, and its materializer can record whichever message you read last, without accumulating events over time.
Event Sourcing & The Web App
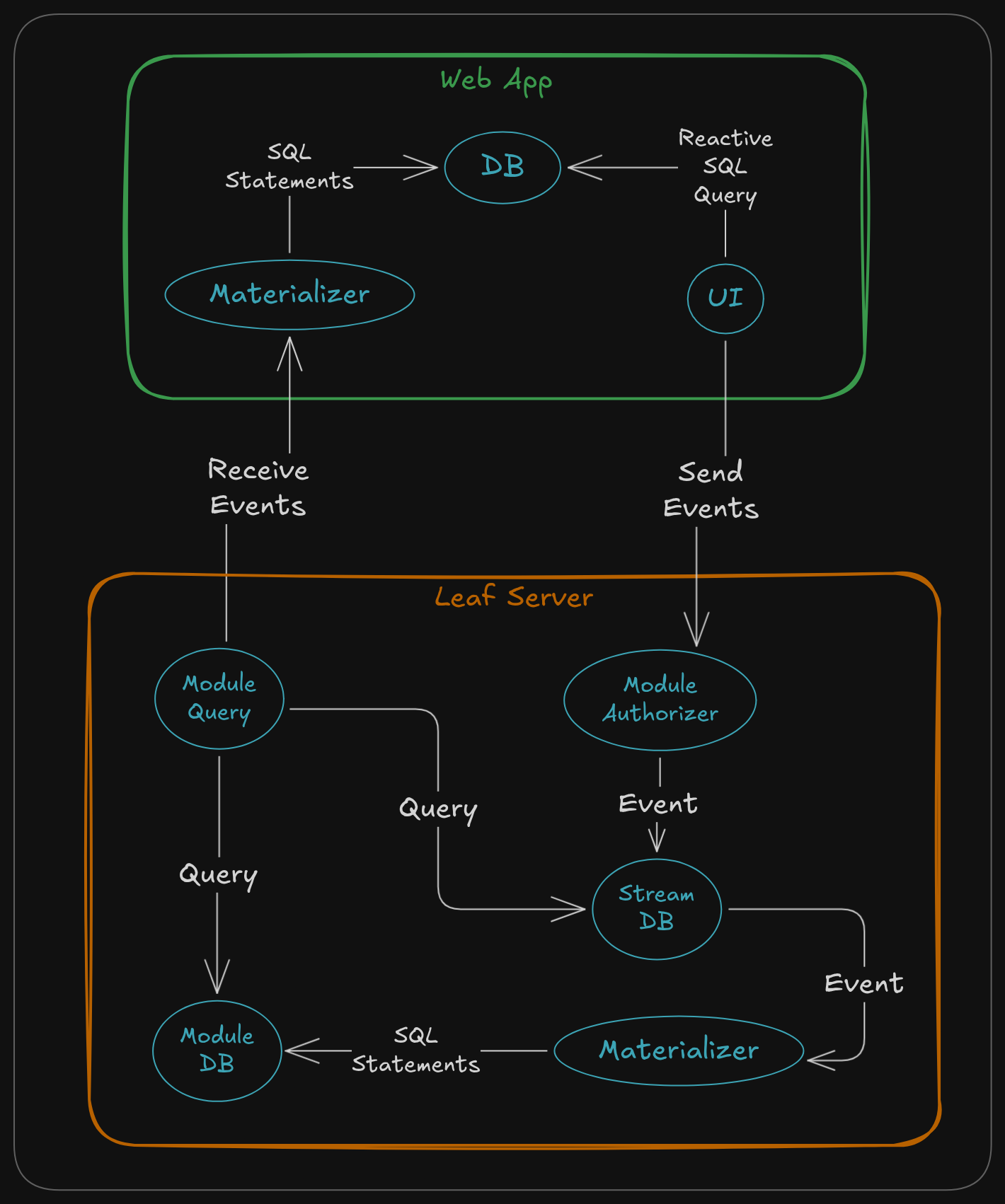
While not strictly required or enforced, the Leaf server focuses on enabling an Event Sourcing workflow.
The Roomy app, for example, creates an event for every user interaction. These events are sent to the server, authorized and indexed by the stream module, and then automatically pushed to any client subscriptions that include it.
Roomy will then take that event and run it through its own materializer, finally storing the event data in a SQLite database, with all the indexes needed to efficiently query the data in the UI.
The UI itself uses reactive queries to that SQLite database so that whenever new events come in, the UI will automatically refresh with the latest results.
The whole flow is pictured below:
Wow, that's... a lot. Is it all really necessary?
It is a lot, but I think it's the best way to get the data ownership, flexibility, and performance that we need long term.
While it is somewhat complicated, in the end I think it is actually one of the simplest ways to solve all the problems we have run into with Roomy's architecture so far. Every design decision has been motivated by our actual needs.
I also think that once the patterns have been worked out a bit more and we have some more tooling in place, that the Leaf server could be useful for a lot more than just Roomy.
I think the fact that modules give you the ability to do aggregations of events on the server, similar to a minimal PaaS, could be really handy for some use-cases, especially when combined with the realtime nature of it.
ℹ️ Note: It's also possible to skip the event sourcing model for the most part on the client and just have the server aggreate all the interesting data and return those results instead of the events themselves. This is all quite new so there's a lot of room for exploring different ways to use things.
How is a Module Written?
So how do you write a module? Is it written in JavaScript or WASM or something?
Right now they are actually just written in SQL!
The authorizer, materializer, and queries are all just made out of lists of SQL statements with access to extra SQL functions we've defined specifically for helping you write Leaf modules.
For example, a simple SQL authorizer could look like:
select unauthorized("Only stream owner can add events")
where (select creator from stream_info) != (select user from event);
And a query that only allows the creator of the stream to read its events could look like:
-- Authorize the query
select unauthorized('only the stream creator can read its events')
where $requesting_user != (select creator from stream_info);
-- Return the result
select id, user, payload from events.events
where id >= $start limit $limit;
There are some kinds of logic which are either impractical or impossible with SQL, so we are considering allowing you to define custom SQL functions in WASM and/or adding a simple DSL or scripting language like Duckscript ( maybe ) as a way to execute conditional SQL statements more easily.
The great part about SQLite is that it's easy to mix in your own DSL / scripting language and execute that code as a part of the SQL transactions.
We've designed the Leaf server so that it's easy for us to implement new kinds of modules using different languages or features in the future.
Summary
There you have it! That sums up most of Roomy's architecture.
We are approaching a full year of focused work on building Roomy and we're zeroing in on our final design. Things may shift, but the core strategy will remain the same and we will make it work.
Postscript: Peer-to-Peer & Local First
Wait up! Didn't you used to talk about things like local/offline first and peer-to-peer tech. What happened to that?
Unfortunately the tech isn't ready yet, and we need to get Roomy into real-world use now.
See A Brief History of Roomy's Architectures for more detail, but, in short, we were going to use Willow, but it wasn't ready yet, then we were going to use Keyhive & Beelay, but that also wasn't ready yet, finally we actually did use Jazz, but ran into serious performance problems and it was missing an essential feature we needed.
While our new design is less peer-to-peer that previous attempts, we are putting a lot of effort into making sure that we have, as much as possible, a smooth road forward into more p2p solutions in the future.
For example, the event sourcing model we are using allows you to make edits offline and later sync those edits to a server, to give us local-first features.
Similar to Git, we can hypothetically have temporary "forks" of a chat space that allow you to chat with someone that you have a LAN connection with, even if you are offline, before later "pushing" those changes to the main "branch".
We have a lot of ideas for potential solutions and I think we're in a pretty good position to make real progress on it once we can find the time. It's something that we are passionate about and it's something that we believe there is real-world value in.
In order to get the time and resources to bring that to fruition, though, we need to start with something that can provide real value to people today, and we think that Roomy can do that.
Time will tell... Now, go get it done!
We're on it!