Leaf, ATProto and ActivityPub
How does Leaf Protocol compare to AtProto and ActivityPub?



As a part of our work on Weird we're developing the Leaf Protocol, an experimental peer-to-peer federation protocol built on top of Willow.
During development we've kept our eye on how ActivityPub and ATProto do things; now seems like a good time to talk about how Leaf compares to prior art.
ATProto & ActivityPub - The Short Versions
Before talking more about Leaf, let's take a look at ATProto and ActivityPub.
ATProto
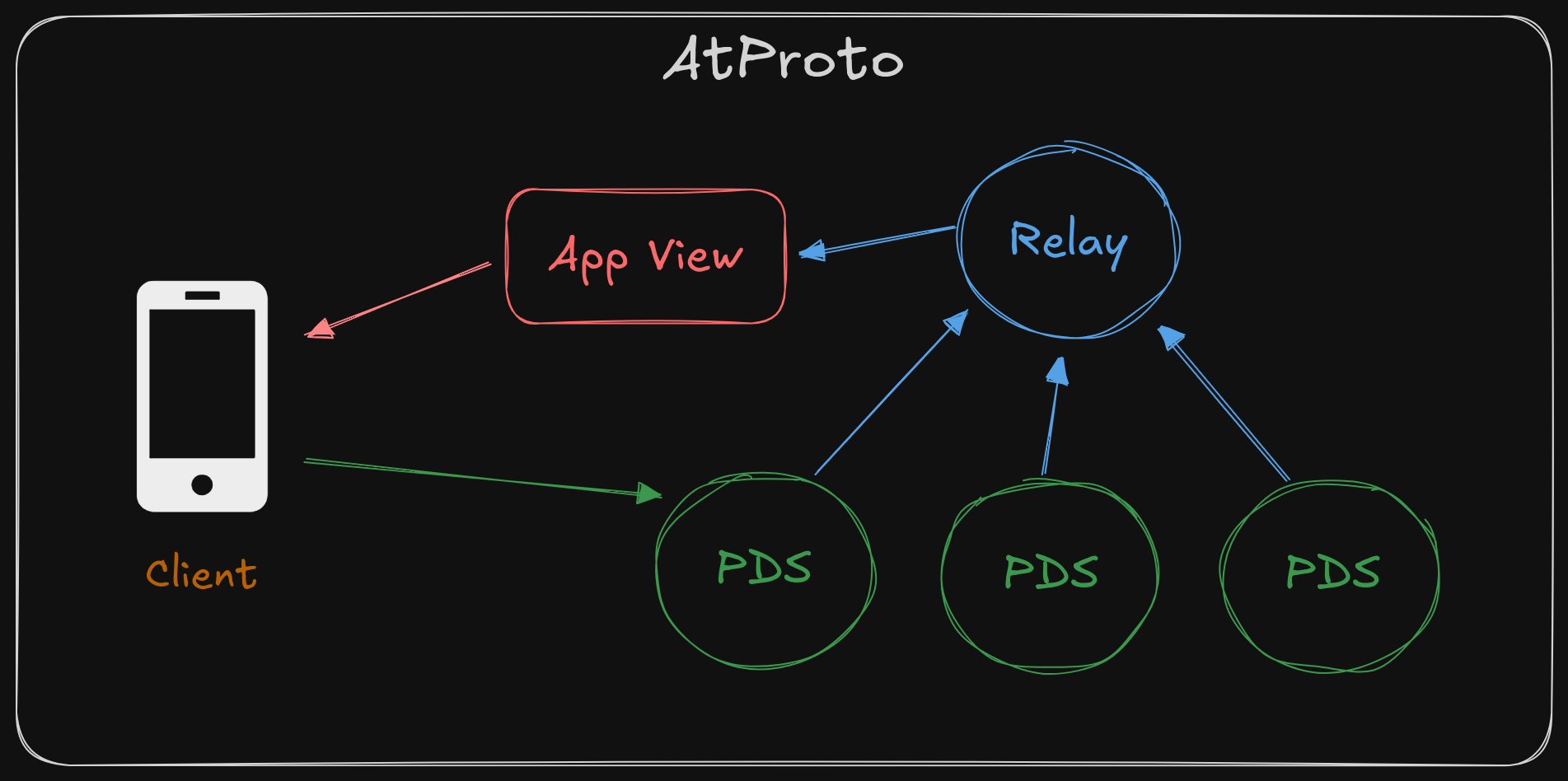
In ATProto users store all their data in their own Personal Data Store ( PDS ). This is cool because you can host a PDS on your own server and have complete control over your data if you want to.
To create the global feeds and notify people when you post something, your PDS will send all of its posts to the big, central Relay.
The relay takes all the messages that it receives from all of the PDSes and it combines them all into what is called the Firehose: basically a stream of every post from everybody.
Because it's really hard to make a nice-to-use app if all you have is a mega stream of messages from the firehose, we need an AppView that listens to the kinds of messages it's interested in, then saves data about those messages in its own database. The AppView presents a nice app API that can be accessed by the Client.
ActivityPub
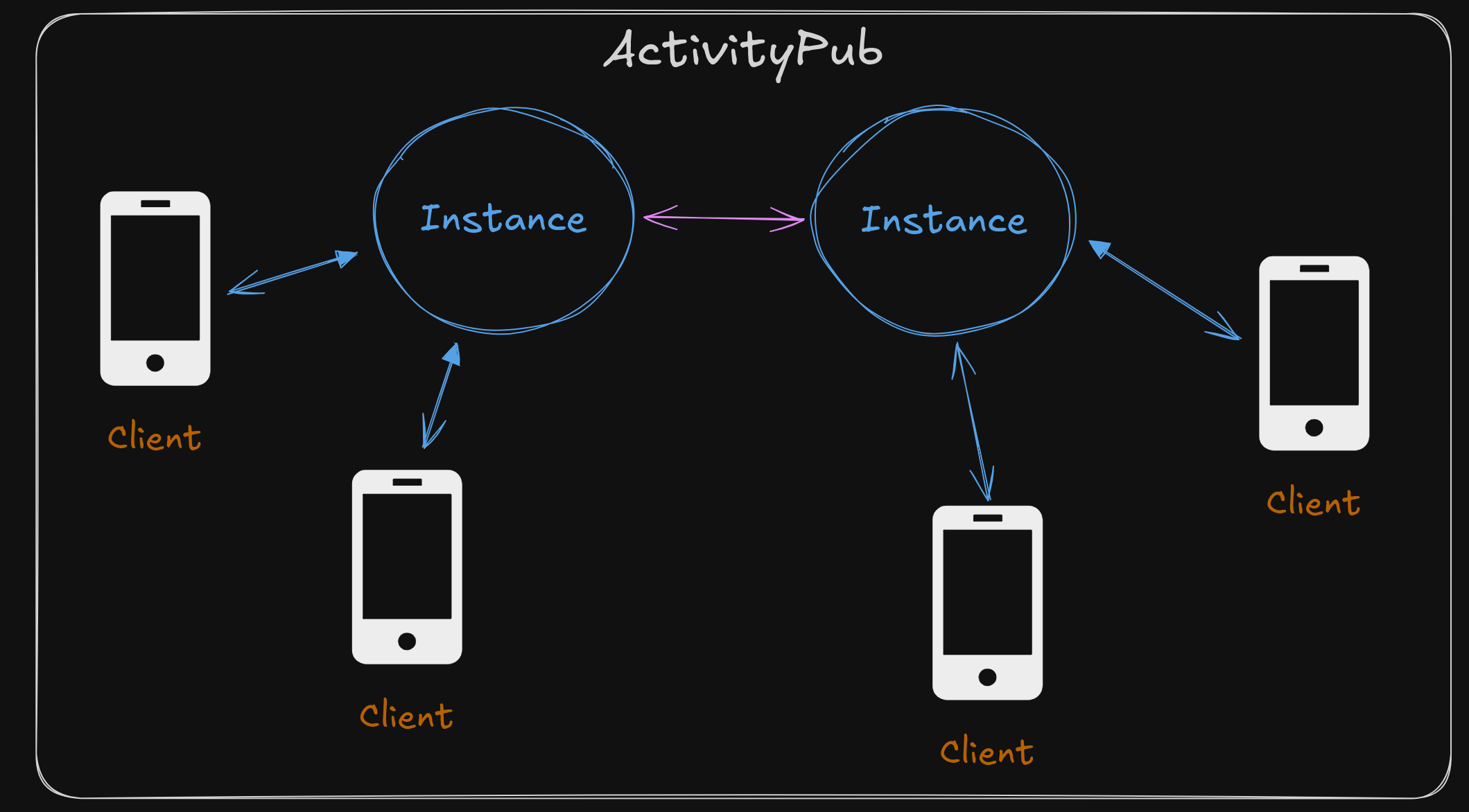
In ActivityPub, all user data is stored in an ActivityPub Instance.
The instance works similar to a traditional server-based web application. The difference is that it also has a concept of Inboxes that allow users to send messages to each-other, even if they are on different instances.
When Alice wants to follow Bob, Alice's instance will send a message to Bob's instance, asking that Bob's new posts be sent to Alice's inbox. Alice is also able to lookup Bob's past posts by using Bob's instance's API.
In this way you end up with a kind of synchronization between instances and a way for you to subscribe to different kinds of notifications from others regardless of which instance their data is on.
Leaf Protocol
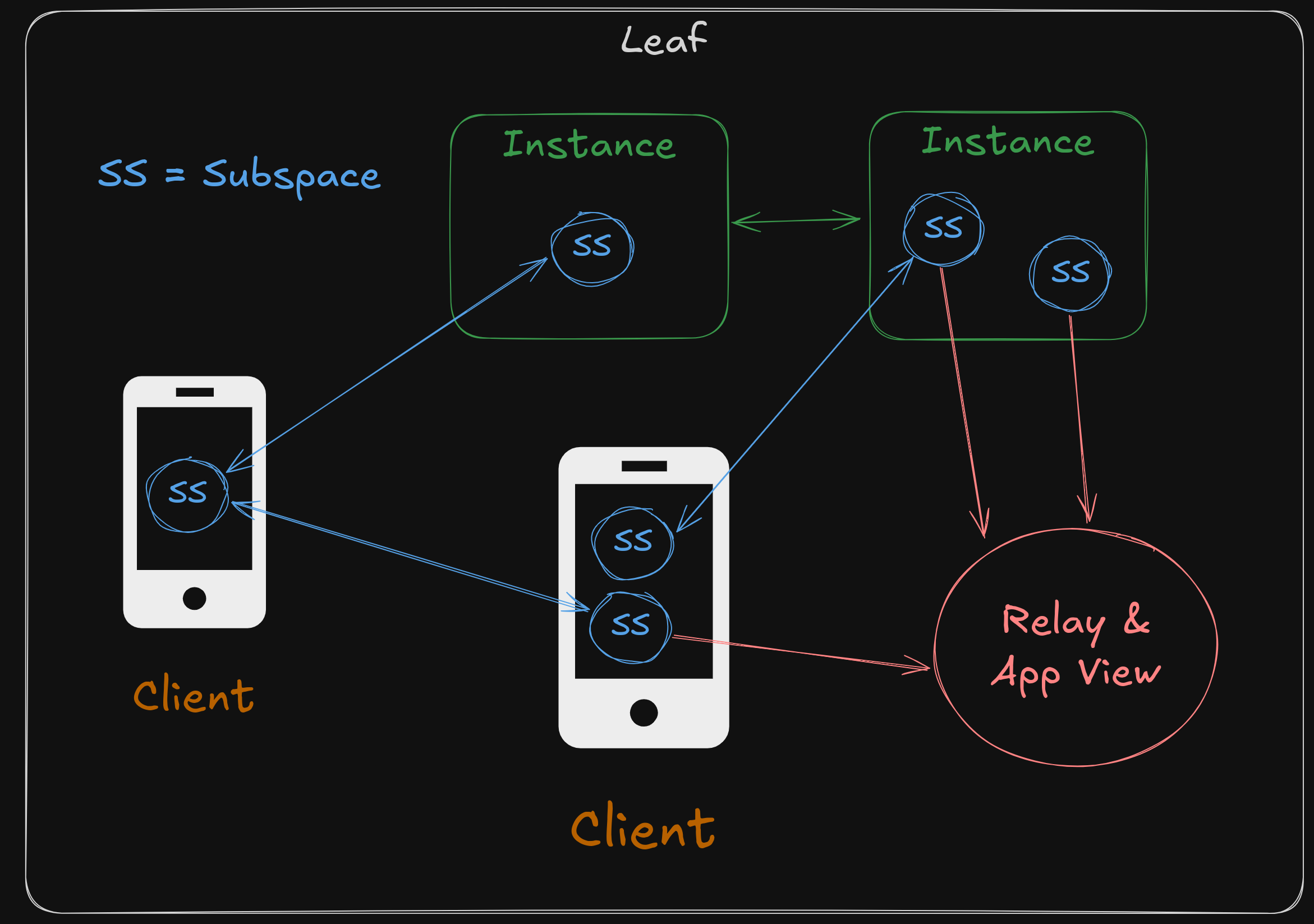
Leaf works by storing all user data in what are called Subspaces.
Subspaces are kind of like a file-system. Data is stored in Entities, which are similar to files, and each one of them has a hierarchical path in the subspace.
All entity data also has a Schema, which is similar to an ATProto Lexicon.
Subspaces themselves are very much like ATProto PDSes: they are a kind of personal data store. Leaf subspaces, though, have some extra super-powers.
Powered by Willow, subspaces have replication built-in: you can synchronize your subspace to your local devices and even edit your data offline.
Subspaces also have a permissions system, enabling you to store private data that can be shared only specific people or services, if desired.
Devices can synchronize subspaces peer-to-peer, without needing servers, allowing you to build local-first workflows.
Using the permissions system, it's also possible to create Inboxes for subspaces just like ActivityPub. You can create a path in your subspace that anybody is allowed to write to, without allowing them to overwrite other people's messages.
This would allow patterns similar to a peer-to-peer ActivityPub, but without your data being tied to a particular instance or web domain.
Adding Servers and Relays
Leaf is inherently a peer-to-peer protocol, but that doesn't mean you can't combine it with servers and relays if you want to.
To scale up to millions of users you could make a relay and app view that would collect data from user subspaces, much like ATProto.
Alternatively you could do something more like ActivityPub where you have server instances that host your data for you when you are offline and act as a safe storage place, but you also have the freedom to replicate your data locally, write posts offline before syncing to the server, and move your data from one server instance to another automatically.
Like ActivityPub, you could subscribe to data from other instances, and Leaf provides an efficient way to replicate data such as attachments securely between the different peers / servers.
This leafy network architecture is very flexible and could be used in any combination of the above ideas, depending on the needs of a social network.
Schema Systems
Above I talk mostly about where data is stored and how it is distributed, but another important aspect of a protocol is how data is encoded and how meaning (semantics) is associated with the data.
ATProto has a custom schema system they call Lexicon and it's similar to JSON schema.
ActivityPub uses JSON-LD and is semi related to schema.org and the RDF standard.
JSON-LD and RDF
One of the common challenges with JSON-LD and RDF is that any document can basically be anything. Every field could come from a different schema. This is handy when modeling data that you want to be able to change over time, or that may need to represent any kind of data.
Why Not RDF? by Paul Frazee explains some of the things that can make RDF sub-optimal.
RDF is kind of like using a dynamic programming language such as Lua, or JavaScript, where any variable could be anything, so if you want to make sure you know what it is you have to check it yourself. That can lead to a less-than-optimal developer experience.
Lexicon
ATProto with its Lexicon standard is more like using a statically typed, Object Oriented programming language. You define your "classes" and an object either matches that class completely, or it doesn't match at all. It's easier to validate and much easier to generate API bindings off of, which is one of the reasons that ATProto went with that solution.
Leaf takes an approach that is exactly in the middle of both of those models and that is inspired by the Entity-Component-System design pattern that is popular in game development.
Leaf Schema
In Leaf, each Entity may store any number of components on it, and each component is required to exactly match a schema. So each component is statically typed, but each entity may have any number of components.
This strikes a balance between the fully dynamic nature of RDF and the fully static nature of Lexicons. Code generation is facilitated very easily by the component schemas, but flexibility is facilitated by allowing an entity to be a combination of different components.
 Zicklag
Zicklag
This pattern has proved very useful in representing the variety of entities that you might encounter in video game development as features and needs develop over time, and I suspect that it can also work very well in the inter-operable application space as well.
It's a Matter of Granularity
Notice that all three data formats, RDF, Lexicon, and Leaf Schemas, can all store any data. There is always a way to losslessly represent any data in any of the three schema systems.
The biggest difference is in the typical level of granularity that you apply when breaking the data up to fit it into the system.
RDF is extremely granular, Leaf is in the middle, and Lexicon is the least granular, but I believe all of them could have their data translated into any of the others. What sets them apart is what kind of development experience is possible with each of them, and how the specific schema standards are developed on them.
In Leaf we avoid this specifically by using content hashes as the IDs for schemas so that it's not possible to change them once issued. Trusted friendly names for schemas that can have their content updated can then be optionally implemented on top of the immutable schemas.
Weird & Websites
To take a slight detour from Leaf itself, I think it's interesting to look at how we are fitting it into the bigger picture.
One of the Bluesky developers wrote a post that explained how ATProto usernames are domains because they are essentially websites. Essentially, but not exactly, because there's no way to visit your Bluesky profile as a website under your domain.
That's an important part of what we are doing with Weird. Your username is a domain, and that domain has a website anyone can visit to see your profile. Your website will eventually be something you can personalize and use to share all of your public data that you store on your personal Leaf subspace.
One of our important goals with Weird and Leaf is to enable people to own their data, even if they can't self host. Leaf allows people to have all their data, replicated in realtime, on their own device, without the hassle of trying to do a slow "download my data" process every time they want to back it up.
We also want to enable people to have their own space on the web. A webpage anybody can visit that is made from the data that they own.
Summary
In emulating the most prevalent patterns of prior art, Leaf can behave as either ATProto or ActivityPub; even both at the same time!
Leaf adds some features we consider crucial, mostly regarding local-first and data ownership — but after establishing that, it can continue to function with a similar mode of operation to the major existing solutions.
Lastly, since we’re comparing Leaf to two protocols mainly known for their microblog-firehose apps, Bluesky and Mastodon, it’s worth mentioning that we’ve no interest in building such an app ourselves. The open social web has already got several great options for that app archetype.
We intend to take the path less traveled. While architecturally Leaf has the most in common with ATProto, the types of spaces we want to enable are more akin to the placeful instances of ActivityPub. There’s a lot still to be said and done for village-scale networks and neighborly webrings.
Time will tell how Leaf and its ecosystem will shape up, but it's encouraging to see how it has organically arrived at familiar patterns. It's just different enough to unlock some great new features for user agency!